
McKinsey Global 기관에 의하면 인공지능이 기존의 분석, 머신러닝, 딥러닝을 통해 11.0~17.7조 달러의 경제적 영향을 끼칠 것으로 추정
오픈AI에서 발간한 “GPTS are GPTS”에서는 대형언어모델의 출시만으로도 미국 노동시장의 80%는 기존 일의 10% 정도 영향이 갈 것으로 전망 나머지 19%는 50%의 영향을 받을 것으로 전망



IDC에 따르면, 2022년부터 2027년까지의 글로벌 AI 시장에서 생성형 AI의 지출이 가장 빠른 성장을 보이며, 연평균 성장률은 약 73.3%에 달할 것으로 전망했다. 이는 기타 AI분야의 성장률인 23.0%와 전체 AI 시장의 성장률인 30.4%를 크게 상회하는 수치이다.


생성형 AI 시장의 크기는 급속도로 커질 것이다
약한 인공지능은 “지능을 모방해 특정 문제를 풀기 위한 기술”이며 강한 인공지능은 “인간처럼 생각하고 감정과 의식을 가지며 창의성을 발휘하는 기계”이다.


머신러닝과 딥러닝의 학습법은 3가지 종류로 ① 지도학습(Supervised Learning), ② 비지도학습(Unsupervised Learning), ③ 강화학습(Reinforced Learning)으로 구분할 수 있다. 지도학습은 정답이 주어져 있는 훈련 데이터를 학습 시켜 정확한 답을 출력할 수 있도록훈련시키는 학습이다
비지도학습은 지도학습과 달리 훈련 데이터에 레이블링 즉 결과물은 없지만 데이터의 특성만을 가지고 학습해서 유의미한 새로운 데이터를 예측한다
마지막으로 강화학습은 모델이 어떠한 상태에서 행동 및 결정을 취했는지에 따라 정답일 경우 보상을 주고 오답일 경우 벌칙을 내리는걸 반복해 점차적으로 모델을 최적화한다.
강화학습은 지도학습과 다르게 정답이 주어지지 않기 때문에 무작위로 행동 및 결정을 하게되며 이에 따라 주어지는 보상과 벌칙을 통해 보상 최대화를 위한 모델로 최적화 시키게된다. 참고로 강화학습은 인공신경망이 학습하는 방법이며 딥러닝으로 이어진다.


딥러닝은 머신러닝의 하위 개념으로 인간의 뇌 신경망처럼 뉴런 네트워크, 즉 인공신경망을 구성하는 것에서부터 시작한다. 인공신경망은 스스로 학습하고 개선하는 대규모 신경망이며 다층 구조(Multi Layer) 형태의 신경망을 기반으로 한다. 결론은 인간처럼 스스로 학습할 수 있도록 인공신경망을 구축해 많은 데이터로 훈련을 거듭할수록 성능이 향상된다
초기형태의 인공신경망인 단층 퍼셉트론은 x=입력값, W=가중치, y=출력값일 경우 인공뉴런에서 보내진 입력값 x는 가중치 W를 적용해 인공 뉴런에 전달된다. 가중치가 클수록 입력값의 중요도가 증가하며 입력값 x와 가중치 W의 곱의 전체 합이 임계치보다 크면 종착지 인공 뉴런이 활성화되면서 1이 출력되고 그렇지 않을 경우 0을 출력한다. 인공신경망은 여러층으로 구성되어 있으며 기본적으로 입력층(input layers), 은닉층(hidden layers), 출력층(output layers)로 구분된다.

GAN(Generative Adversarial Networks)은 적대적 생성 신경망으로 딥러닝 모델의 한 종류이며 생성기(Generator)와 판별기(Discriminator)인 두개의 뉴럴 네트워크로 이루어져 있다. GAN은 이 두 개의 네트워크를 대결하여 학습시켜 실제 데이터 분포에 가까운 데이터를 생성하는 것이 목적이다.
딥러닝의 인공신경망을 통해 다양한 데이터들을 다룰 수 있게 되었다. 머신러닝과 딥러닝의 차이점은 머신러닝 기법은 주로 정형 데이터를 다루지만 딥러닝은 그림, 언어, 음성인식과 같은 지정된 방식으로 정리되지 않은 비정형 데이터 처리가 가능하다는 점이다. 비정형 데이터 처리가 가능해지면서 패턴인식, 미래예측, 신호처리, 자율주행과 같은 활용 사례들이 늘고있다. 예를들면 텍스트 기반의 언어모델 뿐만 아니라 Dalle 혹은 Stable Diffusion과 같은 이미지 모달리티를 학습하고 처리하는 모델이 가능해졌다.


생성형 AI는 유저의 지시에 따라 텍스트, 이미지, 오디오 등 새로운 컨텐츠를 만들어낼 수 있는 인공지능을 말한다. 생성형 AI 기반 모델을 통해 자연어 처리가 가능해지면서 컴퓨터는 기존의 원시 명령어가 아닌 자연어, 즉 인간의 언어를 그대로 입력 받을 수 있게 됐다.
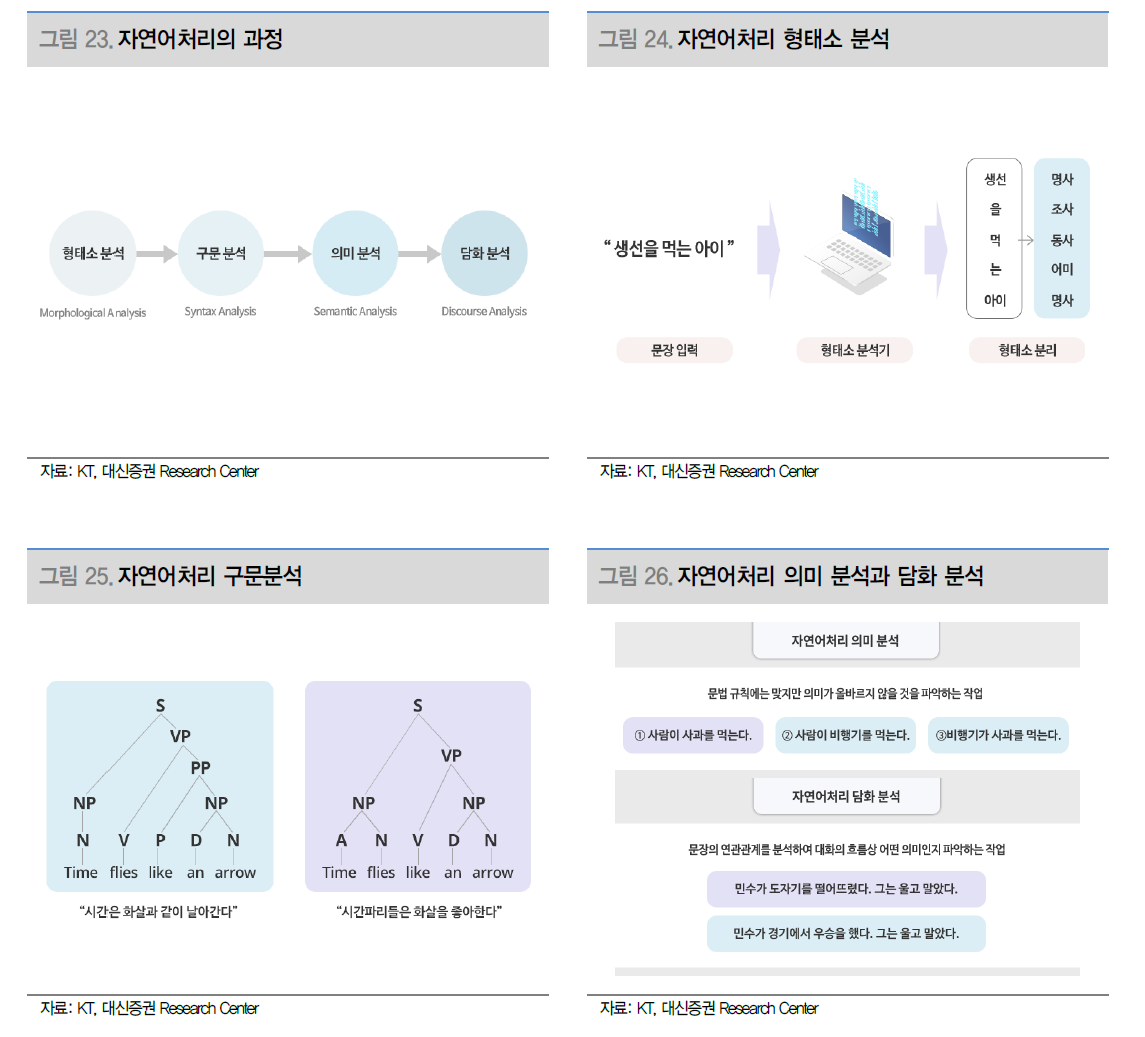
인공지능의 한 분야인 자연어 처리는 머신러닝을 사용해 텍스트와 데이터를 처리하고 해석한다. 위에서 생성형 AI의 기반 모델에서 ChatGPT에게 자연어로 명령을 하고 결과값을 자연어로 받을 수 있는 이유도 자연어 처리(NLP)의 유형인 자연어 인식과 자연어 생성 덕분이다. 자연어 처리는 컴퓨터가 사람의 언어(자연어)를 이해하고 처리하는 과정으로 형태소 분석→구문 분석→의미 분석→담화 분석의 순서로 이루어져있다.
생성형AI는 텍스트, 이미지비디오, 음성음악, 코드 생성 모달리티에서 모델, 시스템, 애플리케이션별로 혁신이 일어난다
모달리티는 정보나 데이터의 유형을 나타내며, 컴퓨터에서 텍스트 처리를 하는 경우 “텍스트 모달리티”, 이미지 데이터를 다룰 경우 “시각 모달리티”, 음성 데이터를 다룰 경우 “오디오 모달리티”로 구분한다
첫 번째 모델 레벨(Model Level)은 이미지, 텍스트, 코드 등 데이터 모달리티별로 AI 기반 모델을 뜻하며, 텍스트 생성의 기반 모델의 예시로 GPT-4, 이미지/비디오 등 Visual 생성형 기반 모델 예시로는 Stable Diffusion과 DALL-E2가 있으며, 코드 생성의 기반 모델은 Codex와 AlphaCode가 있다.
두 번째 시스템 레벨(System Level)의 경우 각각의 기반 모델을 사용해 인터페이스를 제공한 임베딩 모델이 뒤따라오게 된다. 간단한 예시는 오픈AI에서 만든 ChatGPT는 임베딩 모델로 유저들이 GPT-4 기반 모델을 사용할 수 있도록 인터페이스를 제공한다.
마지막으로 애플리케이션 레벨(Application Level)에서는 각 모달리티 분야별로 비즈니스 혹은 이용자의 편의성 제공 및 문제점을 해결한다. 코드 생성 모달리티의 경우, 코딩 생성, 리뷰, 및 문서화에서의 편의성을 증대시킨다. 또한, 텍스트 생성의 경우 컨텐츠 생성부터 번역 서비스 및 텍스트 요약을 제공하게 된다.

멀티 모달은 텍스트, 음성, 이미지, 영상 등 다른 양식의 데이터를 개별 모델로 입력 처리가 가능하며 모달리티간 정보를 교환해 동시에 처리할 수 있다.
오픈AI의 DALL-E2와 LG의 엑사원이 멀티모달 AI의 예시로 들 수 있다. DALL-E2의 경우 사용자가 원하는 이미지를 텍스트로 입력할 경우 이미지 형태로 출력을 한다.


생성형 AI 밸류체인은 크게 네부분으로 1) 인프라(반도체, 클라우드 등), 2) 파운데이션모델, 3) 미들웨어, 4) 애플리케이션 및 서비스로 나누어진다.
이 자료에서는 생성형 AI 밸류체인의 소프트웨어 부분인 기반 모델, 미들웨어, 애플리케이션 및 서비스에 중점을 두고자 한다. 생성형 AI 소프트웨어는 크게 세 가지로 대규모 언어 모델을 구축하기 위한 학습이 이루어지는 ① 기반 모델, 특정 애플리케이션에 적합하게 조정하고 사용하기 쉽게 만드는 ② 미들웨어, 그리고 최종 사용자가 직접 이용하는 소프트웨어 서비스인 ③ 애플리케이션이 있다.
기반 모델(Foundation Model)이란 레이블이 없는 대량의 원시 데이터에서 비지도 학습을 통해 훈련된 머신러닝 모델이다
GPT-3, BERT, DALL-E, Stable Diffusion이 기반 모델의 예시이다



생성형 AI 기반 모델을 통해 자연어 처리가 가능해지면서 컴퓨터는 기존의 원시 명령어가 아닌 자연어, 즉 인간의 언어를 그대로 입력 받을 수 있게 됐다. 사용자가 언어 모델에 입력하는 값과 수준에 따라 결과물이 달라지기 때문에, 앞으로는 프롬프트 엔지니어링이 AI 서비스의 품질을 판단하는 중요한 요소 중 하나가 될 것으로 예상한다. 프롬프트 엔지니어링이란 자연어 처리나 프롬프트(대화형 AI 시스템 명령문인)를 전문적으로 다루는 것을 의미한다
프롬프트 엔지니어링이 중요해지면서 프롬프트를 거래하는 마켓 플레이스들이 생겨났다. DALL-E, ChatGPT 등의 프롬프트를 판매하는 PromptBase와 ChatGPT 전용 프롬프트 마켓플레이스인 FlowGPT가 있다. 마켓플레이스들의 수익 모델은 건당 판매 가격이 기반이며 실제 판매가 이루어질 때 10%의 수수료를 수취하는 방식이다

ChatGPT는 생성형 AI 챗봇 신드롬을 일으켰다고 말해도 과언이 아니다. 2022년 11월 출시되어 생성형 AI와 언어모델의 큰 관심을 불러일으켰으며, 구글의 검색 엔진을 대체할 수도 있다는 주장까지 나올 정도로 센세이션을 일으켰다.

ChatGPT는 사람과 대화형식으로 대화할 수 있도록 만들어진 챗봇이다. GPT(Generative Pre-trained Transformer)는 다음 단어를 예측하는 사전에 대량의 데이터를 훈련한 신경망에 기반한 인코더-디코더를 뜻한다. 즉, ChatGPT는 대화할 수 있도록 GPT 모델을 미세 조정(Fine tuning)한 것을 말한다.
ChatGPT가 자연어로 대화할 수 있게된 이유는 RLHF테크닉이 GPT 모델에 적용되었기 때문이다. RLH는 Reinforced Learning from Human Feedback의 줄임말로 인간의 피드백을 통한 강화학습을 뜻한다. 원래는 GPT-3은 사람이 학습에 개입하지 않는 비지도학습이었지만, ChatGPT는 사람이 직접 개입해 추가학습하는 방법으로 개선되었다. 하지만 사람이 모든 학습에 개입하기에는 비용이 너무 많이 들기 때문에 강화학습이 추가되었다.
ChatGPT 답변 도출 원리는 3단계로 나눌 수 있다. 첫 번째, 사람이 직접 질문에 대한 이상적인 답변을 수기로 작성하여 데이터 세트를 만들고 답변을 기반으로 ChatGPT 모델을 지도 학습시키고 미세 조정하게 되는데 이를 “지도학습 기반 미세조정”(SFT:Supervised Fine Tuning)이라고 부른다.
두 번째, 질문에 대한 답변을 여러 개 추출한 후 사람이 직접 해당 답변에 대한 퀄리티를 평가해 순위를 매긴다. 그 후 리워드 모델은 순위 데이터를 학습해 이상적인 답변을 예측한다.
마지막으로 데이터셋에서 새로운 질문 샘플을 추출해 지도 학습 정책 기반의 PPO(Proximal Policy Optimization)을 구축한다. 그 후 지도 학습 정책 기반으로 질문에 대한 답변을 생성하고 이전에 학습시킨 리워드 모델을 기반으로 질문에 대한 답변을 생성하고 해당 답변 수준을 평가한다. 평가된 리워드를 PPO를 통해 ChatGPT의 지도 학습 정책이 업데이트되며 이 과정을 반복하게 된다.

생성형AI의 밸류체인 중 소프트웨어 단계에서는 위에서 언급한 기반모델, 미들웨어, 애플리케이션 및 서비스로 나뉜다. 생성형 AI가 연계될 수 있는 최종 단계는 사용자에게 제공되는 애플리케이션 및 서비스이다.

ChatGPT의 편리성이 증가함에 따라 점차 포털 사용자들의 AI 수행비서 의존도가 높아질 것으로 예상된다. 이러한 변화는 포털 사이트에서의 체류 시간 감소로 이어질 수 있으며, ChatGPT와 같은 AI 모델에 더 많은 플러그인 기능이 추가될수록 다양한 수행 기능이 확장될 것으로 판단한다.
모바일 스마트폰의 시대가 도래한 이후 휴대폰에 탑재된 운영체제(OS)는 크게 AOS와 iOS로 나눌 수 있다. AOS는 안드로이드 운영체제이며 iOS는 애플의 운영체제이다. 이제는 GPT와 같은 언어 및 생성형 모델들이 다양한 버전과 기능에 사용될 수 있도록 애플스토어와 비슷한 개념인 GPTStore.AI(오픈AI)를 런칭했다.
